순환 신경망(Recurrent neural network)이란 무엇인가?
우선'리커런트 (Recurrent)'라는 단어부터 시작한다.
주기는 빈번하거나 반복적으로 발생하는 것을 의미한다.
이러한 유형의 신경망은 일련의 시퀀스 입력에 대해 동일한 작업을 반복적으로 수행하기 때문에 순환 신경망이라고 한다.
따라서 순환 신경망을 이해하려면 시퀀스 데이터라는 개념을 이해해야 한다.
시퀀스 데이터(Sequence Data)
데이터 세트의 포인트가 데이터 세트의 다른 포인트에 종속될 때마다 데이터를 순차 데이터라고 한다.
이에 대한 일반적인 예는 주가와 같은 시계열 또는 각 점이 특정 시점의 관찰을 나타내는 센서 데이터이다.
시퀀스, 유전자 시퀀스 및 날씨 데이터와 같은 순차적 데이터의 다른 예가 있다.
다음은 잘 알려진 순차 데이터 다운로드 사이트이다.
Dataset의 크기가 일정하지 않음:
문장이나 언어에 포함되는 단어의 수가 정해져 있지 않다.
Data간의 상관성이 매우 큼:
사용되는 동사는 문장의 주제에 따라 다르다(예: 반말과 존 댓 말을).
순서의 의미가 큼:
문장의 의미는 앞뒤 순서에 따라 변화하다.
One-way 정보흐름을 가지고 있음:
뒤에 나오는 data가 앞의 data에 크게 의존하기도하지만, 경우에 따라서는 앞에 나오는 data가 가지는 의미를 알기 위해서는 뒤에 나타나는 data을 알아야한다.
RNN(순환 신경망)이 필요한 이유
합성곱 신경망은 이미 매우 강력하다.
그럼,RNN이 필요한 이유는 무엇인가?
컨볼루션 신경망이 좋은 영역에서는 대부분의 데이터가 정적이라는 것을 인정해야 한다.
입력 데이터는 이미지와 같은 2차원 데이터와 같이 서로 독립적이다.
그러나 의미 인식 및 시계열 분석과 같은 응용 프로그램의 경우 컨볼루션 신경망은 약간 부적절하다.
우리가 이전에 다룬 모든 네트워크(컨볼루션 신경망 포함)는 각 입력은 개별적으로만 처리할 수 있으며 이전 입력과 다음 입력은 전혀 무관하다.
그러나 일부 작업은 시퀀스 정보를 더 잘 처리할 수 있어야 한다.
즉, 이전 입력이 후속 입력과 관련된다.
예를 들어 여자친구에게 '사랑해'라고 말하고 부모님에게 '사랑해'라고 말할 때, 두 '사랑해'의 문자적 의미는 같지만 문맥에 따라 의미가 다르다.
전자는 연애(여자친구와의)를 표현하고, 후자는 감사(부모와)을 표현한다.
그것들은 완전히 다른 의미를 가지고 있다.
따라서 이전 출력을 기반으로 약간의 편차가 필요하며 이것이 RNN의 목적이다.
즉, RNN에는 이전에 시퀀스 데이터에서 발생한 일에 대한 특정 메모리가 있다.
그러나 실제로 이러한 종류의 메모리는 매우 제한적이다.
이전에 완전히 연결된 신경망에서 다음과 같은 그림을 그렸었다.
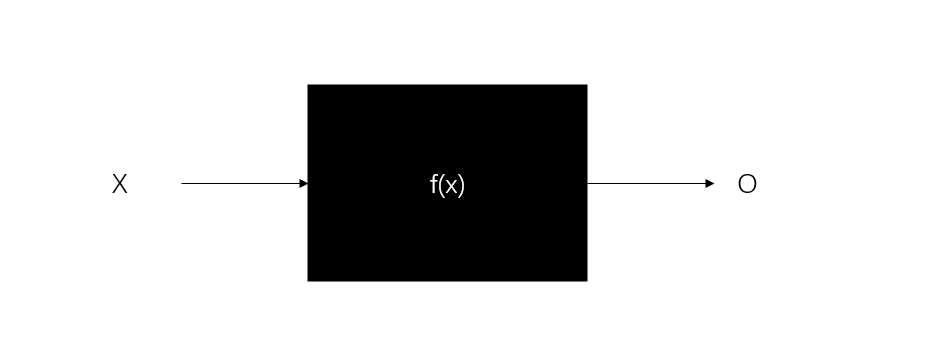
그 기반에 작은 것을 추가하면 순환 신경망의 구조 그림이 될 수 있다.

W가 표시된 화살표 원을 제거하면 가장 기본적인 완전 연결 신경망이 된다.
X는 벡터이며 입력 레이어의 값을 나타낸다.
S는 벡터이며 은닉층의 값을 나타낸다.
O는 출력 레이어의 값을 나타내는 벡터이기도 한다.
W 블록에 대해 이야기하기 전에 RNN 고유의 개념인 '시간 단계(time step)'을 소개해야 한다.
즉, 't-1'단계에서 내린 결정은 't'단계에서 내린 결정에 영향을 미친다.
따라서 W는 은닉층의 이전 시간 단계 값의 가중치 행렬이며, 이들의 내적은 현재 시간 단계 입력의 일부로 사용된다.
핵심은 \(S_t\)의 값이 \(X_t\)뿐만 아니라 \(S_{t-1}\)에도 의존한다는 것이다.
순환 신경망의 계산 방법을 표현하기 위해 다음 공식을 사용할 수 있다.
$$\begin{array}{l}
O_{t}=g\left(V \cdot S_{t}\right) \\
S_{t}=f\left(U \cdot X_{t}+W \cdot S_{t-1}\right)('두\quad개의\quad입력')
\end{array}$$
그 중 U는 입력층에서 은닉층까지의 가중치 행렬이고, V는 은닉층에서 출력층까지의 가중치 행렬이다.
이것은 단순한 추상화일 뿐이고 오프셋과 비선형 변환 부분은 고려하지 않다.
아래에서 RNN의 구조를 자세히 분석해 보겠다.
RNN의 구조
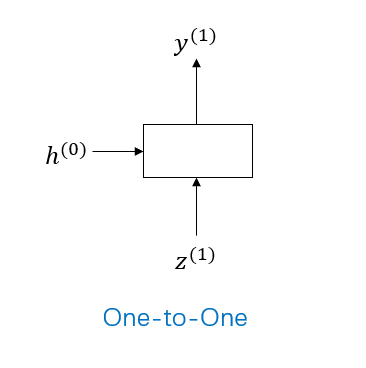
처음 Sequence Model이란, 연속적인 입력(Sequential Input)으로부터 연속적인 출력(Sequential Output)을 생성하는 모델이다.
위의 '두 개의 입력'에 대한 이해를 바탕으로 다음과 같은 많은 시퀀스 모델을 도출할 수 있다.
기호 설명:
\(z^{(t)}\): \(time step\) \(t\)에서의 input값
\(h^{(t)}\): \(time step\) \(t\)에서의 activation값
\(y^{(t)}\): \(time step\) \(t\)에서의 output값
One-to-One 모델:
One-to-Many 모델:
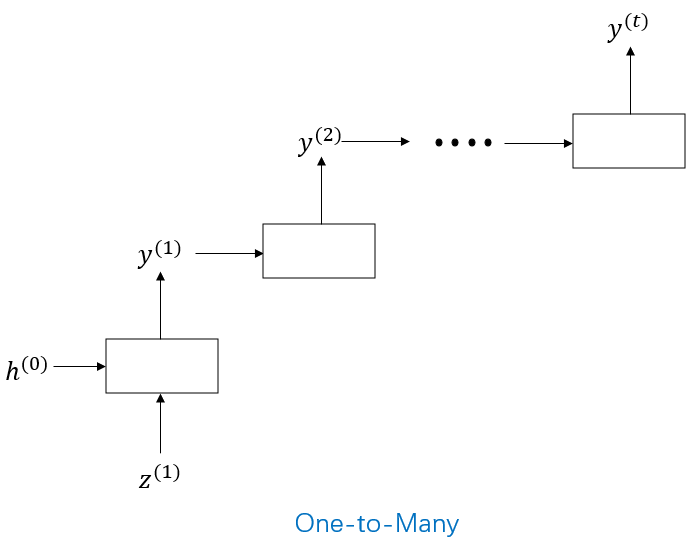
예를 들어:

Many-to-One 모델:
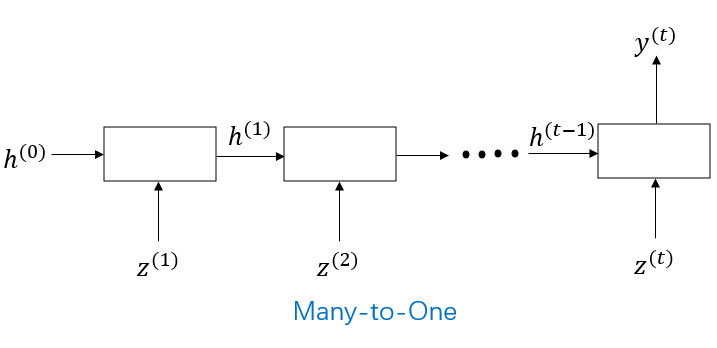
예를 들어:

Many-to-Many 모델:

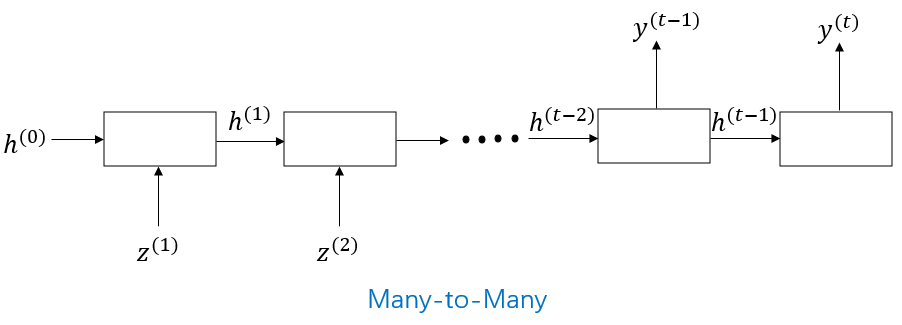
예를 들어:

순차 모델을 이해한 후 그런 다음 간단한 RNN 모델을 살펴봅시다.
즉, 은닉층의 계산 과정을 깊이 관찰하는 것이다.
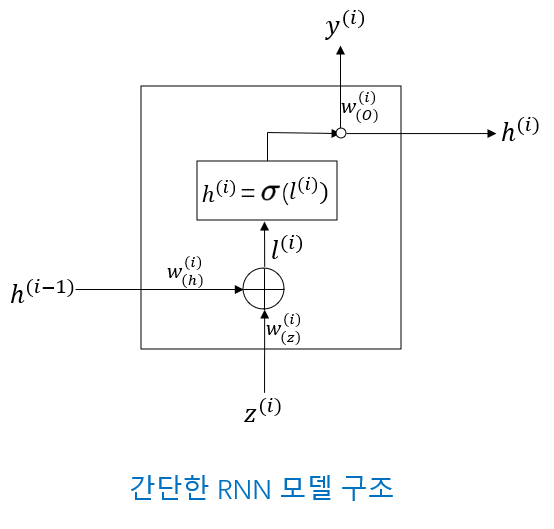
위 그림의 기호 설명:
\(z^{(i)} \in \mathcal {R^d}\): time step \(i\)에서의 input 값
\(h^{(i-1)} \in \mathcal {R^h}\): time step \(i-1\)에서 time step \(i\)로 입력되는 Short-Term Memory 값(활성화 값)
\(h^{(i)}\): time step \(i\)에서 출력되어 time step \(i+1\)로 입력되는 Short-Term Memory(활성화 값) 값
\(y^{(i)}\): time step \(i\)에서의 출력값
이 모델에는 두 개의 입력(지난 활성화한 Short-Term Memory의 값과 이번의 새로 입력한 값)과 두 개의 출력(이번의 새로 출력한 값과 이번의 새로 활성화한 Short-Term Memory의 값)이 있다.
이것이 fcnn(완전히 연결된 신경망)과 rnn(순환 신경망)의 차이이다.정확히 말하자면,
피드포워드 신경망 구조와 비교할 때 순환 신경망의 가장 큰 차이점은 순환 신경망의 출력이 다음 계층으로 전파될 뿐만 아니라,
또한 같은 레이어에서 다음 순간으로 전달할 수 있다.이 '단기 기억'으로 인해 전체 네트워크의 모든 정보는 (가중치를 통해) 상관될 수 있다.
수학 공식은 계산하기 어렵지만 문제나 모델을 표현하고 설명하는데 사용하는 것이 매우 편리한다.
평소와 같이 RNN(모델 계산 프로세스)의 데이터 흐름을 살펴본다.
1.일단은 FCNN과 정확히 동일하고 선형 공식이 하나만 더 있는 두 입력의 선형 연산 부분이다.
$$
\begin{align}
z_{(z)}^{(i)} &= w_{(z)}^{(i)} z^{(i)} + \varepsilon_{(z)}^{(i)} \\
z_{(h)}^{(i)} &= w_{(h)}^{(i)} h^{(i-1)} + \varepsilon_{(h)}^{(i)} \\
\\
\hat z_{(z)}^{(i)} &= \hat w_{(z)}^{(i)} z^{(i)} \\
\hat z_{(h)}^{(i)} &= \hat w_{(h)}^{(i)} \hat h^{(i-1)}
\end{align}
$$(Error\((\varepsilon)\)는 선형 계산을 할 때 좋은 습관이라는 것을 잊지 맙시다. 수학은 엄격해야 하기 때문이다.)
이 두가지를 더하면 선형운산의 결과 \(l^{(i)}\) 가 나온다.
$$
\begin{align}
l^{(i)} &= z_{(z)}^{(i)} + z_{(h)}^{(i)} = w_{(z)}^{(i)} z^{(i)} + w_{(h)}^{(i)} h^{(i-1)} + \varepsilon^{(i)}
= \left[ w_{(z)}^{(i)}, w_{(h)}^{(i)} \right]
\left[ z^{(i)}, h^{(i-1)} \right]^T + \varepsilon^{(i)} \\
&= W^{(i)} Z^{(i)} + \varepsilon^{(i)}
\end{align}
$$
그 중, \(\varepsilon^{(i)} = \varepsilon_{(z)}^{(i)} + \varepsilon_{(h)}^{(i)}\)
단, \(W^{(i)} = \left[ w_{(z)}^{(i)}, w_{(h)}^{(i)} \right], Z^{(i)} = \left[ z^{(i)}, h^{(i-1)} \right]^T\)이면, 위의 공식은 간단하게 다음과 같이 쓸 수 있다.
$$
\hat l^{(i)} = \hat W^{(i)} \hat Z^{(i)} = \left[ \hat w_{(z)}^{(i)}, \hat w_{(h)}^{(i)} \right]
\left[ z^{(i)}, \hat h^{(i-1)} \right]^T
$$
2.그리고 나서 FCNN과 똑같이 선형 연산결과를 비선형적으로 연산한다.
$$
\begin{align}
h^{(i)} &= \sigma \left( l^{(i)} \right) \\
\hat h^{(i)} &= \sigma \left( \hat l^{(i)} \right)
= \sigma \left( \hat W^{(i)} \hat Z^{(i)} \right)
= \sigma \left( \left[ \hat w_{(z)}^{(i)}, \hat w_{(h)}^{(i)} \right] \left[ z^{(i)}, \hat h^{(i-1)} \right]^T \right)
\end{align}
$$
3.마지막으로이 모델에서는 비선형 변환 결과에 대해 선형 연산을 한 번 한 후, 현재 시간 단계의 결과를 출력한다.
$$
\begin{align}
y^{(i)} &= w_{(O)}^{(i)} h^{(i)} + \varepsilon_{(O)}^{(i)} \\
\hat y^{(i)} &= \hat w_{(O)}^{(i)} \hat h^{(i)}
\end{align}
$$
이러한 '순환 신경 노드'가 많이 연결되어 순환 신경망을 형성한다.
여기서 "노드"는 실제로 RNN의 은닉층 하나를 나타낸다.
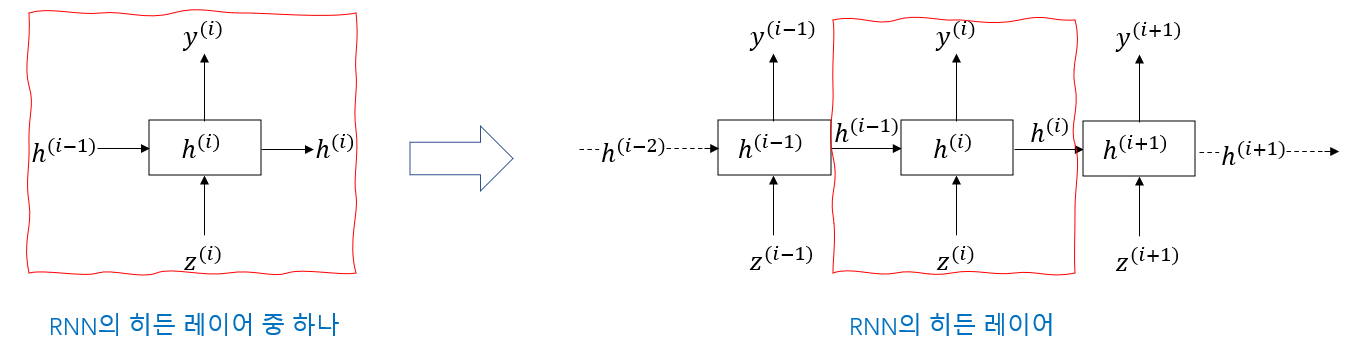
매번 새로운 입력과 실시간 출력을 무시하면 나머지 부분은 처음부터 그 귀여운 '러시아 마트료시카' 였다.
못 믿겠으면 다음 그림을 봅시다.
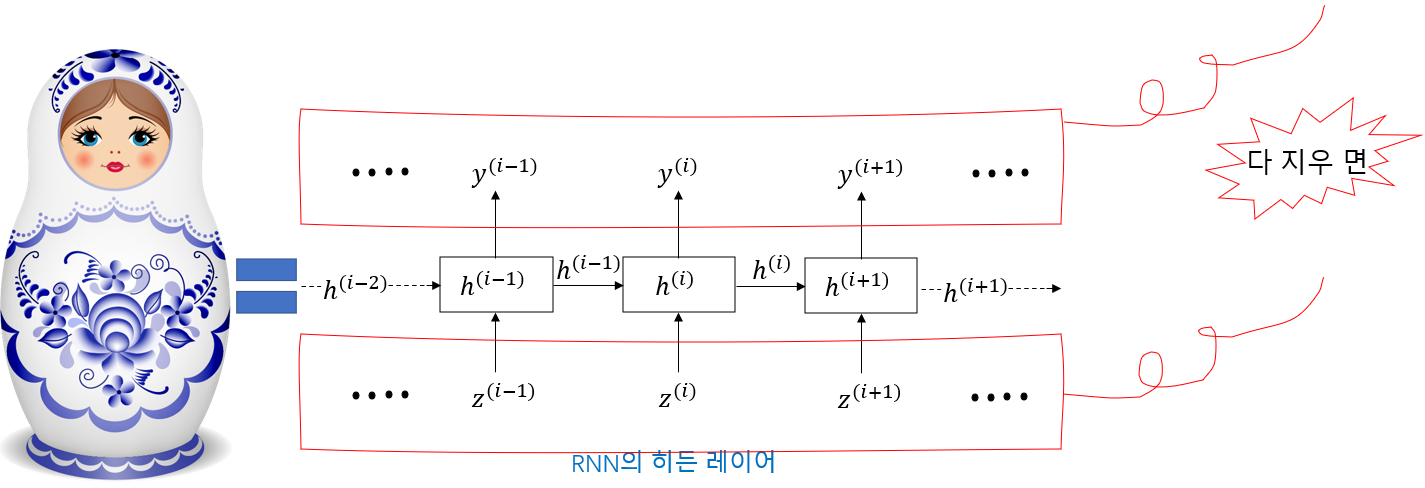
또 수학 공식을 올 려!
\(Time \ Step \ 1: \)
\begin{aligned}
l^{(1)} &=W^{(1)} Z^{(1)} \\
\hat{h}^{(1)} &= \sigma(W^{(1)} Z^{(1)}) = \sigma(\left[\hat{w}_{(z)}^{(1)} \hat{w}_{(h)}^{(1)}\right]\left[z^{(1)}, \hat{h}^{(0)}\right]^{T}) \\
\hat{y}^{(1)} &=\hat{w}_{(O)}^{(1)} \sigma(\left[\hat{w}_{(z)}^{(1)} \hat{w}_{(h)}^{(1)}\right]\left[z^{(1)}, \hat{h}^{(0)}\right]^{T}) \\
\hat{W}^{(1)} &=\left[\hat{w}_{(z)}^{(1)} \hat{w}_{(h)}^{(1)}\right] \\
\hat{Z}^{(1)} &=\left[z^{(1)}, \hat{h}^{(0)}\right]^{T}
\end{aligned}
\(Time \ Step \ 2: \)
\begin{aligned}
l^{(2)} &=W^{(2)} Z^{(2)} \\
\hat{h}^{(2)} &=\sigma(\left[\hat{w}_{(z)}^{(2)} \hat{w}_{(h)}^{(2)}\right]\left[z^{(2)}, \sigma(\left[\hat{w}_{(z)}^{(1)} \hat{w}_{(h)}^{(1)}\right]\left[z^{(1)}, \hat{h}^{(0)}\right]^{T})\right]^{T}) \\
\hat{y}^{(2)} &=\hat{w}_{(O)}^{(2)} \sigma(\left[\hat{w}_{(z)}^{(2)} \hat{w}_{(h)}^{(2)}\right]\left[z^{(2)}, \sigma\left[\hat{w}_{(z)}^{(1)} \hat{w}_{(h)}^{(1)}\right]\left[z^{(1)}, \hat{h}^{(0)}\right]^{T}\right]^{T}) \\
\hat{W}^{(2)} &=\left[\hat{w}_{(z)}^{(2)} \hat{w}_{(h)}^{(2)}\right] \\
\hat{Z}^{(2)} &=\left[z^{(2)}, {\sigma}(\left[\hat{w}_{(z)}^{(1)} \hat{w}_{(h)}^{(1)}\right]\left[z^{(1)}, \hat{h}^{(0)}\right]^{T})\right]^{T}
\end{aligned}
$$\vdots$$
\(Time \ Step \ n: \)
\begin{aligned}
l^{(n)} &=W^{(n)} Z^{(n)} \\
\hat{h}^{(n)} &=\sigma(\left[\hat{w}_{(z)}^{(n)}, \hat{w}_{(h)}^{(n)}\right]\left[z^{(n)}, \cdots \sigma(\left[\hat{w}_{(z)}^{(2)} \hat{w}_{(h)}^{(2)}\right]\left[z^{(2)}, \sigma(\left[\hat{w}_{(z)}^{(1)} \hat{w}_{(h)}^{(1)}\right]\left[z^{(1)}, \hat{h}^{(0)}\right]^{T})\right]^{T})\cdots \right]^{T}) \\
\hat{y}^{(n)} &=\hat{w}_{(O)}^{(n)} \sigma(\left[\hat{w}_{(z)}^{(n)}, \hat{w}_{(h)}^{(n)}\right]\left[z^{(n)}, \cdots \sigma(\left[\hat{w}_{(z)}^{(2)} \hat{w}_{(h)}^{(2)}\right]\left[z^{(2)}, \sigma(\left[\hat{w}_{(z)}^{(1)} \hat{w}_{(h)}^{(1)}\right]\left[z^{(1)}, \hat{h}^{(0)}\right]^{T})\right]^{T})\cdots \right]^{T}) \\
\hat{W}^{(n)} &=\left[\hat{w}_{(z)}^{(n)}, \hat{w}_{(h)}^{(n)}\right] \\
\hat{Z}^{(n)} &=\left[z^{(n)}, \cdots \sigma(\left[\hat{w}_{(z)}^{(2)} \hat{w}_{(h)}^{(2)}\right]\left[z^{(2)}, \sigma(\left[\hat{w}_{(z)}^{(1)} \hat{w}_{(h)}^{(1)}\right]\left[z^{(1)}, \hat{h}^{(0)}\right]^{T})\right]^{T})\cdots \right]^{T}
\end{aligned}
여기서 절편(b)은 고려되지 않다.
그렇지 않으면 다음 공식이어야 한다.
\[\hat{h}^{(t)} =\sigma(\left[\hat{w}_{(z)}^{(t)}, \hat{w}_{(h)}^{(t)}\right]\left[z^{(t)}, \sigma(\left[\hat{w}_{(z)}^{(t-1)} \hat{w}_{(h)}^{(t-1)}\right]\left[z^{(t-1)}, \hat{h}^{(t-2)}\right]^{T}+b)\right]^{T} + b)\]
따라서 제 이해로는 순환 신경망과 피드포워드 신경망의 가장 큰 차이점은 추가 시간 차원이 있다는 것이다.
이를 위해서는 순환 신경망의 입력 데이터가 서로 순서가 맞아야 한다(순서는 최종 결과에 영향을 미친다).그리고 RNN의 recurrent layer에서 같은 layer의 \(W_z\), \(W_h\), \(b\) 파라미터는 활성화 함수 \(\sigma\)를 포함하더라도 서로 다른 시간에 완전히 공유되는데, 이 특성은 recurrent neural network의 파라미터 개수를 크게 줄여준다.
한마디로 서로 다른 순간의 데이터는 같은 뉴런을 사용한다.
RNN의 Forward Propagation과 Backpropagation
위의 기초를 통해 순방향 전파와 역방향 전파 모두 잘 이해된다.
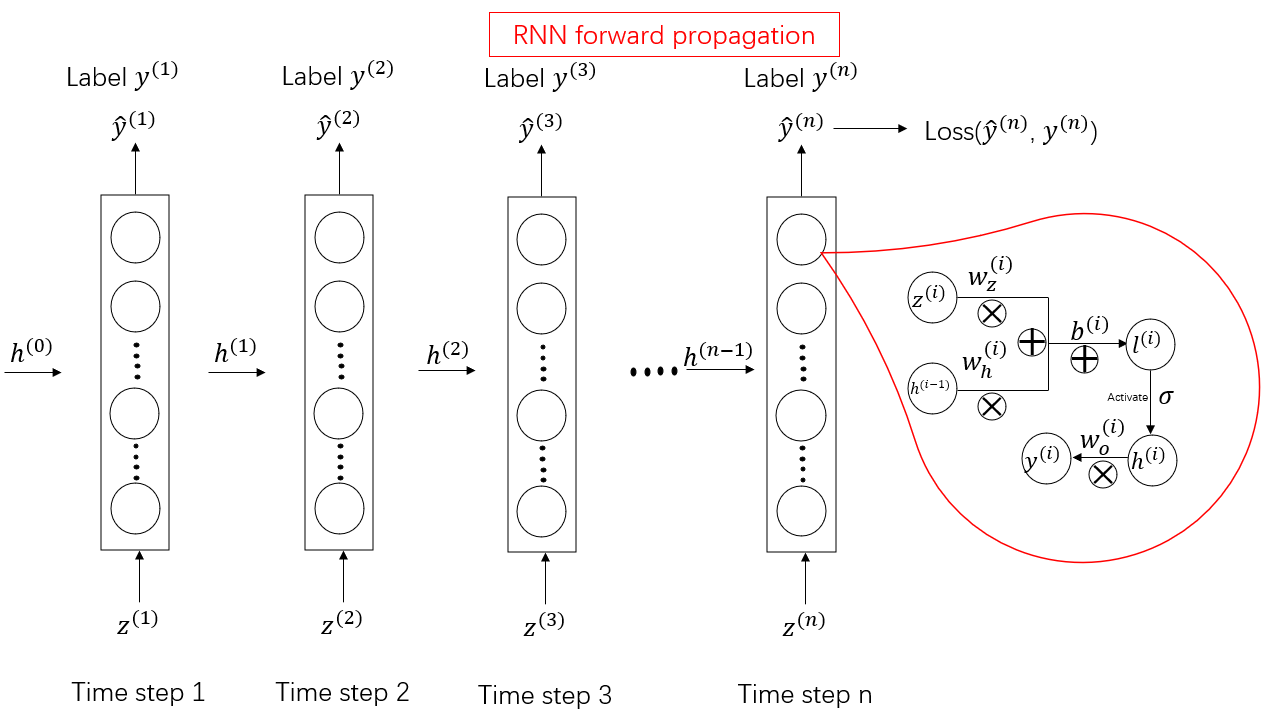
각 노드가 확장된 후 빨간색 원 안에 세부 내용이 표시된다.
역전파는 위와 동일하며 연쇄 규칙을 통해 해당 변수에 의해 전달될 수 있다.
업데이트가 필요한 값에 대한 Loss 값의 편미분을 찾고 최종적으로 경사하강법과 같은 방법으로 값 업데이트를 달성한다.

예:
\(\frac{\partial \text { Loss }}{\partial w_{(z)}^{(i)}}=\frac{\partial \text { Loss }}{\partial l_{(z)}^{(i)}} \times \frac{\partial l_{(z)}^{(i)}}{\partial w_{(z)}^{(i)}}=\frac{\partial \text { Loss }}{\partial h_{(z)}^{(i)}} \times \frac{\partial h_{(z)}^{(i)}}{\partial l_{(z)}^{(i)}} \times \frac{\partial l_{(z)}^{(i)}}{\partial w_{(z)}^{(i)}}= \frac{\partial \text { Loss }}{\partial h_{(z)}^{(i)}} \times \frac{\partial \sigma\left(l_{(z)}^{(i)}\right)}{\partial l_{(z)}^{(i)}} \times z^{(i)}\)
\(\frac{\partial \text { Loss }}{\partial w_{(0)}^{(i)}}= \frac{\partial \text { Loss }}{\partial y^{(i)}} \times \frac{\partial y^{(i)}}{\partial w_{(0)}^{(i)}}= \frac{\partial \text { Loss }}{\partial y^{(i)}} \times h^{(i)}\)



Comments